

[置顶] Linux Lab v1.3 升级部分内核到 v6.6,新增上游内核工具链支持,完善 riscv64 和 nolibc 开发支持,另有新增 2 款虚拟开发板:ppc64le/pseries 和 ppc64le/powernvLinux Lab 发布 v1.3 正式版,升级部分内核到 v6.6,新增 2 款 ppc64 虚拟开发板
bcc 用法和原理初探之 kprobes 注入
By Wu Daemon of TinyLab.org 2020/12/30
eBPF 是现如今最流行的 Linux Tracing 工具,著名的 Linux 性能优化大师 Brendan Gregg 曾说过 “eBPF does to kernel what JavaScript does to HTML”,可见 eBPF 在 kernel 中的重要性。
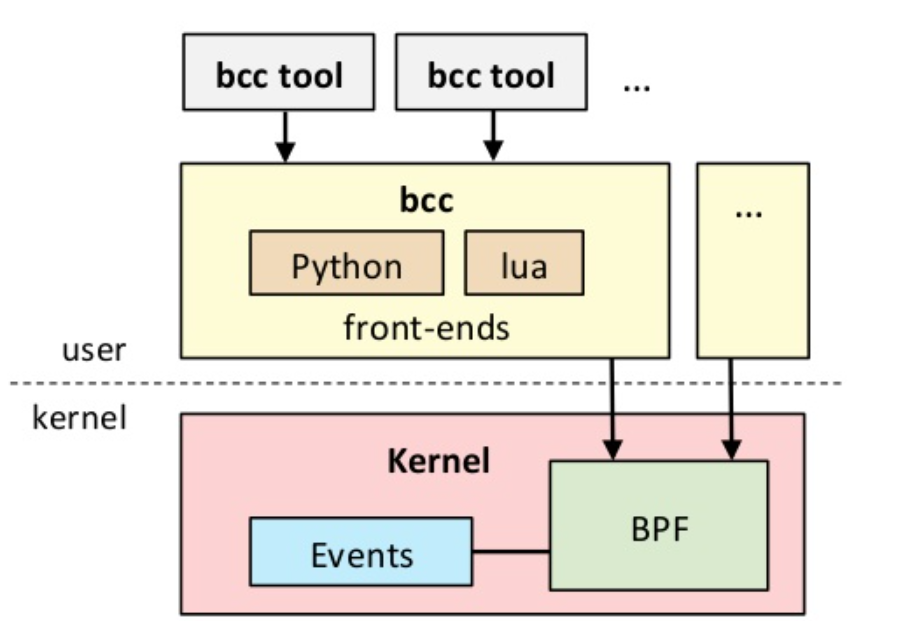
它在用户态注入一段 C 语言代码到内核中运行,然而这一小段代码需要编译成 BPF 指令集的 ELF 格式的文件,而非传统意义上使用 GCC 编译得到的 ELF 文件,这一开始就提高了 BPF 的使用门槛。而 bcc(BPF Compiler Collection)使用 Python 语言做前端,可以通过 Python 脚本注入一小段代码到内核里,这大大降低了使用者门槛。bcc 框架图如下所示:
安装和使用
bcc 工具安装比较简单,有源码安装和使用命令安装两种方式,可参照该链接(注:本文使用平台是 Ubuntu16.04 LTS,Linux 4.4.0)。
安装完成后在 bcc/example 目录下有很多使用案例:
wu@ubuntu:~/work/ebpf/bcc/examples$ tree -L 1
.
├── cgroupid
├── CMakeLists.txt
├── cpp
├── hello_world.py
├── lua
├── networking
├── perf
├── ringbuf
├── tracing
└── usdt_sample
我们以 hello_world.py 作为例子来讲解,其中 BPF(text='xxx') 就是注入内核中的代码,大致意思是当每次调用 sys_clone,也即每次新创建一个 task 就会写 “Hello, World!” 到缓冲区。
from bcc import BPF
# This may not work for 4.17 on x64, you need replace kprobe__sys_clone with kprobe____x64_sys_clone
BPF(text='int kprobe__sys_clone(void *ctx) { bpf_trace_printk("Hello, World!\\n"); return 0; }').trace_print()
调用过程分析
先用 strace 命令追踪一下这个 Python 脚本的系统调用:
wu@ubuntu:/usr/share/bcc$ sudo strace -o hello_world.log python ./examples/hello_world.py
<...>-1383052 [000] .... 577529.457750: 0: Hello, World!
<...>-1383052 [000] .... 577529.461327: 0: Hello, World!
<...>-1383052 [001] .... 577529.465035: 0: Hello, World!
<...>-1383052 [001] .... 577529.470188: 0: Hello, World!
<...>-1383052 [000] .... 577529.474839: 0: Hello, World!
<...>-1383052 [000] .... 577529.476718: 0: Hello, World!
<...>-1383052 [000] .... 577530.477532: 0: Hello, World!
<...>-1383052 [000] .... 577530.479180: 0: Hello, World!
<...>-1383052 [000] .... 577530.480592: 0: Hello, World!
<...>-1383052 [000] .... 577530.481896: 0: Hello, World!
<...>-1383052 [000] .... 577530.483613: 0: Hello, World!
<...>-1383052 [000] .... 577530.484574: 0: Hello, World!
multipathd-669 [000] .... 577530.637946: 0: Hello, World!
multipathd-669 [000] .... 577530.640496: 0: Hello, World!
使用 strace 命令跟踪下,每一次创建一个新进程就会打印数据,其中重要的系统调用如下,由调用过程可以得出 echo "p:kprobes/p_sys_clone_bcc_1877 sys_clone" >/sys/kernel/debug/tracing/kprobe_events,实质是设置了 kprobe_events。
execve("bcc/examples/hello_world.py", ["bcc/examples/hello_world.py"], [/* 16 vars */]) = 0
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=15, insns=0x7ff02a0d57d8, license="GPL", log_level=0, log_size=0, log_buf=0, kern_version=263396}, 120) = 3
... ...
open("/sys/kernel/debug/tracing/kprobe_events", O_WRONLY|O_APPEND) = 4
write(4, "p:kprobes/p_sys_clone_bcc_1877 sys_clone"..., 40) = 40
close(4) = 0
open("/sys/kernel/debug/tracing/events/kprobes/p_sys_clone_bcc_1877/id", O_RDONLY) = 4
read(4, "1127\n", 4096) = 5
close(4) = 0
perf_event_open(0x7ffe474efea0, -1, 0, -1, PERF_FLAG_FD_CLOEXEC) = 4
ioctl(4, PERF_EVENT_IOC_SET_BPF, 3) = 0
ioctl(4, PERF_EVENT_IOC_ENABLE, 0) = 0
openat(AT_FDCWD, "/sys/kernel/debug/tracing/trace_pipe", O_RDONLY) = 5 // 动态输出
... ...
分解如下:
通过 bpf() 系统调用加载 bpf 程序
首先,打开 Python 脚本,然后使用 bpf 系统调用,运行该 bcc 脚本最重要的是执行 bpf 系统调用,第一个参数 BPF_PROG_LOAD,表示加载 bpf 程序。
execve("bcc/examples/hello_world.py", ["bcc/examples/hello_world.py"], [/* 16 vars */]) = 0
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=15, insns=0x7ff02a0d57d8, license="GPL", log_level=0, log_size=0, log_buf=0, kern_version=263396}, 120) = 3
在 Ubuntu 中使用 man bpf 查看 bpf 系统调用,int bpf(int cmd, union bpf_attr *attr, unsigned int size)
cmd:第 1 个参数
BPF_MAP_CREATE
创建一个 map,并返回一个 fd,指向这个 map,这个 map 在 bpf 是非常重要的数据结构,用于 bpf 程序在内核态和用户态之间相互通信。
BPF_MAP_LOOKUP_ELEM
在给定一个 map 中查询一个元素,并返回其值
BPF_MAP_UPDATE_ELEM
在给定的 map 中创建或更新一个元素(关于 key/value 的键值对)
BPF_MAP_DELETE_ELEM
BPF_MAP_GET_NEXT_KEY
在一个特定的 map 中根据 key 值查找到一个元素,并返回这个 key 对应的下一个元素
BPF_PROG_LOAD
验证并加载一个 bpf 程序。并返回与这个程序关联的 fd。本文分析只关注这个 cmd。
bpf_attr:第 2 个参数
该参数的类型取决于 cmd 参数的值,本文只分析 cmd=BPF_PROG_LOAD 这种情况,其中 prog_type 指定了 bpf 程序类型,eBPF 程序支持 attach 到不同的 event 上,比如 Kprobe,UProbe,tracepoint,Network packets,perf event 等。hello_world.py attach 到 kprobe event。
cmd=BPF_PROG_LOAD 使用,本文待分析的:
struct { /* Used by BPF_PROG_LOAD */
__u32 prog_type; // 此 bcc 脚本设置为 BOF 程序的类型,设置为 `BPF_PROG_TYPE_KPROBE`,表示是通过 kprobe 注入到内核函数。
__u32 insn_cnt;
__aligned_u64 insns; /* 'const struct bpf_insn *' */
__aligned_u64 license; // 指定 license
__u32 log_level; /* verbosity level of verifier */
__u32 log_size; /* size of user buffer */
__aligned_u64 log_buf; // 用户buff
__u32 kern_version;
/* checked when prog_type=kprobe
(since Linux 4.1) */
};
size:第三个参数
表示上述 bpf_attr 字节大小。
通过 perf_event_open 系统调用启动 perf 性能分析
调用 perf_event_open 创建一个 fd,允许测试 kernel 相关性能信息,每个 fd 对应一个 event,详细信息可参看 man perf_event_open
函数原型:
int perf_event_open(struct perf_event_attr *attr,pid_t pid, int cpu, int group_fd, unsigned long flags)
pid=-1 && cpu=0,表示策略所有 cpu 上的所有
group_fd=-1 ,获取单个 event 需要设置为-1
flags=PERF_FLAG_FD_CLOEXEC,表示能够在必要的时候自动关闭 fd
strace 探测到的:
perf_event_open(0x7ffe474efea0, -1, 0, -1, PERF_FLAG_FD_CLOEXEC) = 4
通过 perf_event 的 ioctl 调用把 BPF 程序 attach 到 kprobe event
PERF_EVENT_IOC_SET_BPF,表示允许 attach BPF 程序到 kprobe event 上,其中 ioctl 设置的第三个参数代表 bpf 系统调用的 fd。PERF_EVENT_IOC_ENABLE,表示使能 event。
ioctl(4, PERF_EVENT_IOC_SET_BPF, 3) = 0
ioctl(4, PERF_EVENT_IOC_ENABLE, 0) = 0
输出结果到 trace_pipe
attach BPF 程序到 kprobe event 上后,当触发了 kprobe 事件,相关信息就会输出到 trace_pipe 这个缓冲区。
openat(AT_FDCWD, "/sys/kernel/debug/tracing/trace_pipe", O_RDONLY) = 5
debugfs 版本 kprobe event 使用接口分析
通过 debugfs 设置 kprobe event
Kprobe 怎么处理异常,Linux Kprobes 一文已经讲的很详细,现在介绍如何通过 debugfs 接口使用 Kprobe,通过 insmod 加载 Kprobe 模块比较麻烦,debugfs 提供了注册、注销、使用 Kprobe events 的功能,详细请参看:Documentation/trace/kprobetrace.txt。
可通过以下 debugfs 节点可以方便操作 Kprobe:
- 配置接口:
/sys/kernel/debug/tracing/kprobe_events - 读取信息接口:
/sys/kernel/debug/tracing/trace - 开启某个 kprobe 接口:
/sys/kernel/debug/tracing/events/kprobes/<EVENT>/enabled - 过滤接口:
/sys/kernel/debug/tracing/events/kprobes/<EVENT>/filter
其中配置属性文件用于用户配置要探测的函数以及探测的方式与参数,在配置完成后会在 events/kprobes/ 目录下生成对应的目录。
设置 kprobe event 的格式为:
p[:[GRP/]EVENT] [MOD:]SYM[+offs]|MEMADDR [FETCHARGS] : 设置一个 kprobe
r[:[GRP/]EVENT] [MOD:]SYM[+0] [FETCHARGS] : 设置一个 kprobe 断点执行完后的 event
-:[GRP/]EVENT : 清除一个 kprobe
GRP : Group名. 如果省略,则使用 "kprobe" 这里指定为 “p_sys_clone_bcc_1877”
EVENT : Event名. 如果省略, event 名根据 "SYM+offs" 或者探测地址来生成
MOD : 给定符号名的模块名
SYM[+offs] : 符号名+偏移
MEMADDR : 另一种探测输入格式,直接给定探测地址
FETCHARGS : 用户给定的参数,可以实现更多的功能,每个 event 可以指定最多 128 字节的参数。
使用方法可参考以下步骤:
- 设置 kprobe event
$ echo "p:kprobes/p_sys_clone_bcc_1877 sys_clone" > /sys/kernel/debug/tracing/kprobe_events
- 查看相关 event 目录
$ cd /sys/kernel/debug/tracing/events/kprobes/p_sys_clone_bcc_1877
$ tree
.
├── enable
├── filter
├── format
├── id
└── trigger
- 查看 format,也就是
trace_pipe的打印格式
$ cat format
name: p_sys_clone_bcc_1877
ID: 1127
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1;signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:unsigned long __probe_ip; offset:8; size:8; signed:0;
print fmt: "(%lx)", REC->__probe_ip
- 使能 kprobe
root@ubuntu:/sys/kernel/debug/tracing/events/kprobes/p_sys_clone_bcc_1877# echo 1 > enable
- 此时在
trace_pipe或trace节点可查看到追踪内容
root@ubuntu:/sys/kernel/debug/tracing# cat trace_pipe
gpg-agent-2078 [000] d... 890.677086: p_sys_clone_bcc_1877: (SyS_clone+0x0/0x20)
gpg-agent-2078 [000] d... 890.677243: p_sys_clone_bcc_1877: (SyS_clone+0x0/0x20)
anacron-862 [000] d... 927.388340: p_sys_clone_bcc_1877: (SyS_clone+0x0/0x20)
sh-8843 [000] d... 927.389688: p_sys_clone_bcc_1877: (SyS_clone+0x0/0x20)
run-parts-8844 [000] d... 929.087210: p_sys_clone_bcc_1877: (SyS_clone+0x0/0x20)
0anacron-8845 [000] d... 929.101818: p_sys_clone_bcc_1877: (SyS_clone+0x0/0x20)
anacron-8846 [000] d... 929.102555: p_sys_clone_bcc_1877: (SyS_clone+0x0/0x20)
systemd-1 [000] d... 929.117847: p_sys_clone_bcc_1877: (SyS_clone+0x0/0x20)
debugfs 版 kprobe events 实现分析
接下来我们初略的分析下 debugfs 中 kprobe event 的实现过程。
根据代码 kernel/trace/trace_kprobe.c 可知在 kernel 初始化的 fs_initcall 阶段,就调用了 init_kprobe_trace 来实现 kprobe_events,并指定了 kprobe_events_ops 这个 file_operation。当用 echo 操作 kprobe_events 这个节点时,调用 probe_write,注册 kprobe event。
static const struct seq_operations probes_seq_op = {
.start = probes_seq_start,
.next = probes_seq_next,
.stop = probes_seq_stop,
.show = probes_seq_show
};
static int probes_open(struct inode *inode, struct file *file)
{
int ret;
if ((file->f_mode & FMODE_WRITE) && (file->f_flags & O_TRUNC)) {
ret = release_all_trace_kprobes();
if (ret < 0)
return ret;
}
return seq_open(file, &probes_seq_op);
}
static const struct file_operations kprobe_events_ops = {
.owner = THIS_MODULE,
.open = probes_open,
.read = seq_read,
.llseek = seq_lseek,
.release = seq_release,
.write = probes_write,
};
/* Make a tracefs interface for controlling probe points */
static __init int init_kprobe_trace(void)
{
struct dentry *d_tracer;
struct dentry *entry;
if (register_module_notifier(&trace_kprobe_module_nb))
return -EINVAL;
d_tracer = tracing_init_dentry();
if (IS_ERR(d_tracer))
return 0;
entry = tracefs_create_file("kprobe_events", 0644, d_tracer,
NULL, &kprobe_events_ops);
... ...
/* Profile interface */
entry = tracefs_create_file("kprobe_profile", 0444, d_tracer,
NULL, &kprobe_profile_ops);
... ...
return 0;
}
fs_initcall(init_kprobe_trace);
注册 kprobe events 相关调用顺序如下所示,最终调用的是 __register_trace_kprobe 来实现真正的注册过程。
probes_write
create_trace_kprobe
register_trace_kprobe
__register_trace_kprobe
__register_trace_kprobe 的实现细节如下所示,其中令人醒目的是调用了 register_kprobe ,这个就到了注册 kprobe 过程,这个可以参看内核目录下的一个样例 kprobe_example.c,看看注册要哪些参数,这里可以猜测到 struct trace_kprobe 结构体中的 rp.kp 指定了探测符号和偏移量,这里就不一一分析了,读者可根据这个看看详细 kprobe events 怎么注册的。
/* Internal register function - just handle k*probes and flags */
static int __register_trace_kprobe(struct trace_kprobe *tk)
{
int i, ret;
if (trace_probe_is_registered(&tk->tp))
return -EINVAL;
for (i = 0; i < tk->tp.nr_args; i++)
traceprobe_update_arg(&tk->tp.args[i]);
/* Set/clear disabled flag according to tp->flag */
if (trace_probe_is_enabled(&tk->tp))
tk->rp.kp.flags &= ~KPROBE_FLAG_DISABLED;
else
tk->rp.kp.flags |= KPROBE_FLAG_DISABLED;
if (trace_kprobe_is_return(tk))
ret = register_kretprobe(&tk->rp);
else
ret = register_kprobe(&tk->rp.kp);
if (ret == 0)
tk->tp.flags |= TP_FLAG_REGISTERED;
else {
... ...
}
return ret;
}
小结
本文给出了 bcc 使用方法,以及调用过程的基本流程,这只是一个学习 BPF 的第一步。怎么加载 BPF 程序,BPF 字节码是怎么构成的,BPF 怎样在用户态和内核态之间通信等等都是需要慢慢学习的。
参考文献
- https://lwn.net/Articles/740157/
- https://lwn.net/Articles/742082/
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
