

[置顶] Linux Lab v1.3 升级部分内核到 v6.6,新增上游内核工具链支持,完善 riscv64 和 nolibc 开发支持,另有新增 2 款虚拟开发板:ppc64le/pseries 和 ppc64le/powernvLinux Lab 发布 v1.3 正式版,升级部分内核到 v6.6,新增 2 款 ppc64 虚拟开发板
[置顶] Linux Lab v1.2 升级部分内核到 v6.3.6,升级部分 QEMU 版本到 v8.0.2,新增 nolibc 和 NOMMU 开发支持,另有新增 4 款虚拟开发板:ppc/ppce500, arm/virt, loongarch/virt 和 s390x/s390-ccw-virtio。Linux Lab 发布 v1.2 正式版,新增 4 款虚拟开发板,支持 LoongArch, Linux v6.3.6 和 QEMU v8.0.2
实用同步原语伸缩技术
如何设计高性能的锁定原语
原文:Scalability Techniques for Practical Synchronization Primitives 作者:Davidlohr Bueso, SUSE Labs 译者:Chen Jie
译之前言
随着多核的普及,程序越趋并发设计,并发间的同步效率问题逐渐突出。SUSE 实验室的 Davidlohr Bueso 最近总结了内核锁用到的伸缩性技术:Scalability Techniques for Practical Synchronization Primitives,本文为其翻译。
正文
在理想世界中,程序应随硬件扩充而自动伸缩。然在实践中,不仅未见伸缩,反而在扩充后常见性能退化。
性能和伸缩性 可以是个含糊不清的术语,但当问题集中于软件栈较底层时,它显得不是那么明显。这仅是因为评估某个性能退化问题时,需考虑的因素的数量。如此,在并发多线程程序中,例如操作系统内核、管理程序(hypervisors)以及数据库引擎,不合理地使用硬件资源可能会被坑得很惨。
这些对于软件栈上层的应用而言,表现为性能问题。一个明显的例子:为共享内存系统而设计和实现同步原语(锁)。锁通过互斥,为多线程并发执行提供安全正确的上下文。为实现串行化,通常需要硬件支持,例如 CAS (compare-and-swap),fetch-and-add 以及算数指令(arithmetic instructions)等原子操作。虽然此中细节在不同的缓存一致性架构上,表现各不相同,但原子操作会在内存总线上广播更新:更新共享变量在各核上缓存的副本,强制 cache-line 作废 —— 这会增加 cache-line 未命中的情形。软件工程师经常滥用这些原语,。
锁的正确性和性能依赖于其下硬件,故设计锁定算法时,要充分考虑伸缩性和硬件。糟糕的是,在实际编写软件中,很少这么做。
这年头,多核 NUMA(non-uniform memory access)系统越做越“大”,而实现不佳的锁便越显其衰。性能的衰退,不仅因锁设计不佳,更在于锁的使用上 —— 即供多数开发者直接操作的、数据串行访问的锁用案。这是个在数十年研究后的今天,已被周知的事实。虽说近期有些新技术,如锁省略(lock elision)和事务内存(transactional memory),对一线开发者而言,并发、并行编程及同步问题仍是极富挑战的课题10。
多说一句,事务内存系统,例如 TSX(Transactional Synchronization Extensions),在事务失败时,仍需跑一个使用普通锁的备选代码路径,故上述挑战绝不会短期内消失。另外,一个事务系统并不保证具体过程中不发生饿死,故在普通的锁定方案中,从来不是一个可行项。由此带来的复杂性,不仅会导致系统缺乏伸缩性,也在整体性能中存在瓶颈。先前工作告诉我们,用一个糟糕的、非伸缩的锁的实现,会在核数增加时付出怎样的代价2。性能的陡降可能很突然就开始了,就在某个点上加了一些核后。性能和伸缩性问题,不仅仅模拟负载和基准评测中有,现实软件同样有。
近期,在大型高端服务器上,Linux 内核的锁伸缩性问题,取得重大进展3。许多问题和解法,对类似系统软件有着借鉴意义。本文阐述通用的思路,及更宽系统语境下习得的经验,希望能有所帮助。当然,锁在任何共享内存的系统上都很重要,关注优化也不能忘了更重要的:如何用好锁,以及明白哪些数据需要串行化访问。
混搭锁模型和乐观旋等
锁定原语,在无法立即锁定时通常有两类行为:忙等待 或 阻塞。若锁定的时间很短,例如串行化引用计数操作,最好采用让 CPU 忙等待 而不是代价更大的 阻塞式。忙等待通常实现为循环执行 CAS 调用,直到条件成立。另一种阻塞式,则是进行阻塞,直到条件成立。该方式的开销和延时更高,并且通常的,严格依赖操作系统内核的调度器。于是,线程调度策略越来越在乎前次执行,位于软件栈哪一层,例如硬件,内核还是各个用户空间层。不同调度策略对锁的公平性和确定性有很大影响。
实现可睡眠锁的另一要点,是避免“颠簸”现象。一线开发人员应当考虑,锁激烈竞争情形时的系统表现。忙等待式的名例,就是内存屏障(memory barriers)和自旋锁(spinlocks)。阻塞机制常常包含 信号量 和 监听者们。以 Linux 内核为例,有三种主要的睡眠信号量: mutexes(binary) 和另两种计数的信号量,后者的一个广泛使用的变种就是 读者和写者。
使用混搭模型,是一种取各型锁的优点,避其缺点的常见方式。其目标在于尽可能推迟阻塞,在此之前保持乐观忙等直到锁获得。判定何时进行阻塞影响着性能。判定算法需在各种工作负载下表现均衡,但各负载的受益点也许不同。换言之,对于明确需要睡眠锁的情况下,大部分情况下无需忙等太长才发现其实需要阻塞。另外,对于通用锁定原语而言,应确保使用者无法影响其算法行为。设计较差的锁定 APIs 可能导致之后不可预测,例如当锁被重度使用时。一个设计优异的锁接口应呈现简洁性。
Linux 内核有一个“锁的所有者”概念,即指向当前持有本锁的任务的指针。由此两重好处:作为关键数据决定何时停止旋等;同时有助调试,例如用于死锁检测。类似的策略可追溯到 1975 年,那时,锁所有关系的概念在数据库中被首次提出8。由于维护锁的所有关系有开销,实现者可以放弃可重入锁,该锁通常还需用到一个计数域15。
乐观旋等背后的基本原理是,若持有锁的线程正在运行,那么该线程大概会很快释放该锁。在实践中,Linux 内核中最常用的两类锁,mutex 和 rw_semaphore(读者-写者信号量),在获取锁过程中,依据当前状态,分为 3 路径12:
- 快速路径 Fastpath 。首先尝试原子指令(fetch_and_add 或 原子减),修改内部计数来获取锁。实现的逻辑与架构相关,x86-64 上的 mutex 的锁定和解锁操作的 fastpath 仅有两条指令,如下:
0000000000000e10 :
e21: f0 ff 0b lock decl (%rbx)
e24: 79 08 jns e2e
0000000000000bc0 :
bc8: f0 ff 07 lock incl (%rdi)
bcb: 7f 0a jg bd7
中间路径 Midpath (即乐观旋等)。锁的所有者运行期间,且无更高优先级任务就绪待运行,便进行旋等。旋等的线程们由 MSC 锁来安排排队,确保只有一个旋等线程能完成锁定。
慢路径 Slowpath 。作为最后一招,即前两招过后,仍然未取得锁,任务便进入等待队并睡眠,直至在解锁的代码路径中被唤醒。
混搭的锁仍可能阻塞,故上述这些原语只能用在可睡眠的上下文中。乐观旋等在操作系统内核 Linux 和 Solaris 中被证实有效。即便是今天,延后任何形式的阻塞开销,对系统软件仍有重大性能影响。在某个 Linux VFS(Virtual File System)create+unlink 微测试中性能完爆 mutexes —— 日常桌面系统上测得乐观旋等带来了 3.5 倍吞吐量提升。类似的,在 AIM7 负载中,采用混搭锁定的 rw_semaphores 带来了 1.8 倍吞吐量提升3。
Linux 内核中,rw_semaphores 和 mutexes 之间一个显著的差别在于如何处理锁的所有者。相比互斥锁,共享锁中的所有关系变得模糊不清。在既有读者也有写者的工作负载中,乐观旋等可能让写者旋等太久 —— 此时多个读者持有锁,故不是旋等单个“所有者”。解决的策略存在,例如使用启发式和魔数来决定何时停止旋等读者。读者的“所有关系”实现需要些小窍门,由此给乐观旋等的 fastpath 中带来了额外的开销和复杂性。更多的,在锁定原语实现中使用魔数,可能带来意外后果,故轻易不能用。启发式,正如其含义,正常情形下有损性能,只在特殊场景下起作用。伸缩性不是为 1% 情形进行优化,而不考虑此外 99% 情形。另外,解决竞争的实际来源是一个有效的替代方案,而不是把原语搞得特别复杂。
锁伸缩性差的原因
我们常会探究某个时刻下,锁性能太差的诸多因素。这些因素的影响,在每个系统及工作负载中千变万化。这些因素及锁的属性,可按照软件工程层级进行划分:实现者,设计和实现锁定原语;和用户,在并行和并发工作负载/算法中严谨地使用锁。
临界区的长度 。减少临界区的长度定能缓解锁的竞态。这当中锁实现采用什么样的原语,来串行化并发多线程访问,对性能而言至关重要。持有锁走在 slowpath 中,例如锁有竞争时的获取和释放操作,经常需要管理内部等待队列。该队列中的线程等着被唤醒,来进行下一步动作。这种情况下,实现者得保证临界区够短,以免不必要的内部竞争。例如,预检查和唤醒(对于睡眠的原语而言)能够很简单地实现为异步,无需额外串行化。最近,Linux 内核开发者进行了缩短 mutexes 和 SysV 信号量(以及其他形式的IPC)临界区的活动,性能上取得重要提升3,13。
锁的开销 。这是使用特定锁时,资源上的开销,这包括 尺寸 和 延时。例如,内嵌在结构体中的锁,会使结构体变大,这意味着更多的 CPU cache 和内存占用。故对一个系统各处常用的结构体而言,其尺寸是个关键。实现者增加某类型锁的尺寸,进行大修改后,应慎重考虑锁开销,因为这可能导致未预料位置的性能问题。例如,Linux 内核文件系统和内存管理方面的开发者,必须特别关注 VFS struct inode(index node)和 struct page 的尺寸,并竭力优化之4。两者相应代表了系统中每个文件的信息和物理页帧。由此,越多的文件/内存,越多的结构体实例需处理。常能见到在某些机器上有数千万缓存的 inodes,此时, inode 尺寸增加 4% 就会产生重大影响,够让一个良好平衡的工作负载,变成一个内存不堪容纳 inodes 的囧境。实现者必须时刻关注锁定原语的尺寸。
再来说说延时,忙等待原语因其简单,比更复杂的锁有延时上的优势。初始化调用,尤其是锁定和解锁调用,得开销少,即消耗最少的 CPU 周期。主导原语的内部逻辑,不应与其他影响调用延时的因素混淆。阻塞(或者说睡眠)锁预期开销会更大一些,因其必须经历将线程转入睡眠,及锁可用时将线程唤醒。其适用场合为保护较大临界区,或在例如内存分配等可能睡眠的上下文中。服务质量保证(QoS)是另一个选 忙等待 还是 阻塞 的考虑因素,尤其在实时系统上。而在更大的 NUMA 系统上,阻塞会导致根本上得不到资源而饿死系统。
另外,读者-写者原语,在共享和排斥路径上的延时可能不对称。这可不是一个理想状态,用户可能不得不考虑比如共享时的额外开销。更糟的是,用户可能都没意识到这种不对称,于是共享锁的使用拉低了性能。读与写操作的比例(后文提到)是决定读者锁的“共享锁定操作”是否值得引入额外开销的重要因素。一言蔽之,误选锁类型,会带来不必要开销从而严重损害性能。
锁的粒度 。粒度是指锁保护的范围,这是个 复杂度 和 性能 的取舍。较粗粒度,趋于简单化,使用更少的锁来保护大临界区。而细粒度为改进性能,引入一组锁的用案,尤其用在激烈竞争锁的情形下。设计并发算法时,粗粒度锁因其简单而可能被误用,特别是与细粒度锁相比,用起来更直接。同步中的问题,例如死锁、竞态条件、常规损坏,尤其难调试。仅出于对这些不确定性的担心,且“保护多了总比保护不够要好”,程序猿可能更喜粗粒度锁。
更糟的是,这些问题轻易就造成整个系统不可靠 —— 几乎不可用的状态。即便是对锁有经验的程序猿,也可能未留意到伸缩问题,忽视了换成细粒度锁其实能带来潜在的性能提升,直到问题被报告出来。现已被替换的 BKL(Big Kernel Lock)大概就是 Linux 内核中最著名的粗粒度锁。在响应系统调用时,它串行化了进入内核空间的线程。这个锁保护了这么多数据,也被叫做巨锁。内核中另一处受粗粒度锁摧残的地方是 Futexes 。在一个链式哈希表(chained hash-table 译者:是指位筒是个链表)结构中,仅在哈希冲突发生时,保护链表的自旋锁才可能被激烈竞争。这时,简单地增加下哈希表的尺寸就好了。该方法能最高 8 倍地提升哈希表的访问吞吐量3。上述这种细粒度锁技术,也称作 锁剥离,即通过许多锁来串行化数组或链表中各个不同的独立元素的访问。
当然,粗粒度锁也有其用处。其中重要一个原因就是分成数个锁的开销,某些情况下,其多余的内存占用可能会抵消其缓解竞争的好处。滥用细粒度锁与滥用粗粒度锁一样会有害性能。另外,在极少数情况下,即当竞争不是一个问题,临界区锁定时间很短时,粗粒度锁非常适合。
在理论研究和实践中,结合粗和细的粒度能改善性能,虽然这样做挺复杂的。在 Hurricane 内核中,这种结合了各种粒度的混合锁策略被提出16。超过二十年的时间里,Linux 内核处理 semtimedop(2) 系统调用时,饱受 SysV 信号量实现的粗粒度锁拖累。针对调用中的常见情形,即任务等待操作信号量数组中的单个信号量,引入一个细粒度锁模型,测试显示吞吐量暴增 9 倍以上13。这种混合策略也直接影响了重要的 关系数据库系统(relational database management system)的负载,该负载内部严重依赖这些信号量来锁定,改进后竞争状况从约 85% 降至 7%。操作一个以上的信号量时,IPC(inter-process communication)中仍可能有粗粒度的锁定。锁的粒度必须一开始考虑周详,之后再改是个艰巨且易出错的事。
读与写的比例 。这是只读临界区域 与 之可修改区域的数量的比例。读者/写者锁,用于优化处理这些场景,即多个读者共同持有锁,或是写者排他性地持有锁来修改数据。许多研究和工程开发针对几乎全是读的情形进行优化,即读者方面的同步操作开销尽可能小,而写者方面的开销就通常要大些。其例子有 RCU(read-copy update)机制的各变种,序号锁(seqlocks),及 FreeBSD 中的 read-mostly 锁(rmlocks)。
一个著名的例子是 Linux 内核大量使用 RCU,无锁的读者可与写者共存。读者实际上并未持有某个锁,故免除了传统读者/写者锁所需开销,是个极快的机制。RCU 更新数据过程为:(1) 通过读写单个指针,来让更新对读者可见,从而确保修改前后的读者正常执行;(2)延后数据结构的销毁,直到所有读者离开其临界区,无读者引用待销毁的数据结构。类似垃圾收集的方式。RCU 在 2.5 版本期间被引入,即 21 世纪初的时候,内核中很多地方用了 RCU,例如 伸缩 dentry(directory entry)cache,NMI(onmaskable interrupt),及进程号处理11,这不是个巧合。最近,将 epoll 的控制接口从原来一个全局的 mutex 改进为 RCU,文件描述符的增加和移除可同时进行,狠狠改进了下性能。具体到应用,一些 HP 和 SGI 大型 NUMA 系统上的基于 Java 的重要工作负载,因此获得最多 2.5 倍的吞吐量提升。
公平 。公平最重要的意义在于防止等锁的任务挨饿。在竞争锁时,通过使用严格的法则来选择哪个等待的任务来取得锁。一个常见的、不公平的自旋锁是不管已有线程在排队等,任何线程都可获得锁,例如:总是同一个线程不断获得锁。不公平的锁似乎能最大化吞吐量,但产生了较高的调用延时。如果前述情形发展成为一种“病态”,任务饿得半死和进度不走 —— 这在现实软件中就是不可接受的。对此一个广泛使用的解法是采用排队自旋锁(ticket spinlocks)的不同变种。公平锁即针对饥饿问题,但会增加对抢占的敏感度1,6 —— 当抢占不可控时(例如用户空间的应用),公平锁偶尔会显得苍白。如果内核的 CPU 调度器 抢占了某个即将获得锁的任务,而锁此刻正好被释放,那么剩下等锁的线程不得不傻等被抢占的任务再次被调度。类似的,锁获取或释放的代价越大,排队时间巨长的概率也越大,导致性能低下。
从实验来看,不公平锁在每核有一个以上线程时挺有用的,即在高度竞争情形下,比公平锁要好7。当然,由于线程们不得不等待更长时间来获得锁,该问题在 NUMA 系统上尤为突出,特别是当公平锁导致了要命的 cache-line 状况,后文详述之。
从统计来看,可在 NUMA 系统上实现不同级的公平。例如,考虑 CPU 节点的局部性,线程对本地内存节点上的锁可谓是“近水楼台先得月”。将各种忙等待锁改造为 NUMA 优化的原语,从而解决部分问题,这便是 cohort 锁(译者:直译过来叫同伴锁)。其思路为,写者锁在同一 NUMA 节点的各竞争线程间传递,而读者仍共享同一节点上的资源。
处理 读/写 锁时,“公平”呈现出另一种状况,具体取决于上下文、工作负载以及读者与写者的比例。有些情况下让读者优先,有些情况下则相反。不论哪种方式,锁实现者应当注意,不要让读者,或者写者线程挨饿致某些情况下表现很糟。一个可选的做法是对同一个读/写原语,实现带有不同的公平优先级的各变种,但这样做分的情形太多,易误用。基于性能考虑,Linux 内核引入一个 rw_semaphore的 “偷写者锁”概念,打破写者间严格的 FIFO(first-in first-out,先入先出)秩序,即后来的写者可插到队头,直接获得锁。
Cache-line 的不当处理 。在大型 NUMA 系统上执行底层锁定原语时,性能退化的两个最糟表现大概就是 cache-line 的“反复”(bouncing)和“竞争”。竞争锁时,任务会在某个密集的 CAS 循环中不断尝试加载锁的 cache-line。细看循环中的每一轮,通常是在原子上下文(atomic context)下,含有锁的那行数据在各 CPU cache 间移动。简单增加 CPU 个数,就能看到这种反复带来的性能退化 —— 不断消耗宝贵的内存和互联总线的带宽。更糟的是当受锁保护的数据也在同一个 cache line 时,会严重拖慢已获得锁的线程,从而延长锁的持有时间。
解决 cache-line 反复的一个直接做法,CCAS(compare compare-and-swap)技术,早在 30 年前就被提出14。思路就是简单读下锁的状态,仅在锁没人用时再进行 read-modify-write(读取-修改-写回) CAS 操作。Linux 内核中,mutexes 和 read/write 信号量进行排他性获取时(注意:共享方式获取锁时,不需 CAS),会检查内部计数,该操作即是基于 CCAS 技术。具体测试中,对于 mutexes ,在 16 插座共 240 核的系统上,某个基于 Java 的负载能看到最多 90% 的吞吐量提升3;AIM7 测试是一个大部分运行在内核空间的负载,该测试在 8 个节点,80 核心 的 Westmere 系统上也有最多 3 倍的吞吐量提升。对于读/写信号量,跑在 4 核桌面系统上的 pgbench 测试,使用 1GB 的 PostgreSQL 数据库,能看到有最多 40% 的性能改进。大多数 cache-line 反复 被显著改善的例子中,mmap_sem 是被高度竞争的,该锁有个作用是串行化对地址空间的并发操作。
总之, 实验显示 CCAS 技术能在 4 个及以上插槽或 NUMA 节点,这样高大上的系统中起作用。通常而言,非竞争时检查计数的开销也非常低,故对于小一点的系统,也不会过多拉低性能。性能优化工作中,必须总是确保在低端硬件上不产生退化,这对 Linux 内核尤为重要,谁让它有那么那么多的用户呢。
解决本段问题的另一个技术就是采用退避算法 - 针对旋等锁时昂贵的 CAS 操作下手,从而缓解 cache-line 反复和内存互联开销。同 CCAS 技术一样,思路也是延后密集循环中的 read-modify-write 调用。其主要差别在于锁定不成时,延时多少。大量研究试图从多个系统和负载中找到一个最佳的延迟参数。这间各种算法和启发方式可分成静态和动态两类。静态法,延后一个固定时间,对某个特定的负载有效,但必然负于通用情况。于是,更可行的是延后动态的时间,但启发式推断有额外开销,及推断错误会造成负面影响 - 线程不该退避太长时间,这会抵消退避本身所带来的好处。
退避算法中好的启发式会基于正在竞争锁的 CPU 数量,例如比例式和指数式的,类似以太网的二进制指数退避算法(CSMA 退避算法,carrier sense multiple access)。最佳的延迟时间,需要估算临界区长度,及锁持有者释放锁 到另一线程获取之的间隔6,15。不用说,现实中鲜有工作负载能带有这些信息。另外,退避算法也同普通的 CAS 和 CCAS 自旋锁一样,并未针对此情形:所有线程旋等同一个共享的地址,致每次成功获取锁以后,总有缓存一致协议流量。由此,很容易理解,Linux 内核为何不采用退避算法,即便排队自旋锁(ticket spinlocks)加上成比例退避策略(proportional backoff strategies)看起来很有前途5。
展示 Cache-line 竞争效应
锁定和并发的唯一目就是,通过正确地多线程并行执行,改善系统性能。即便是在单核、抢占调度的系统上,通过并发能够假装出一个 多任务系统。若锁定原语拖性能后腿,那它们就是残的,根本没弄好。不像正确性的问题,“残锁”只有在越大的硬件上才越凸显。
在一个现代的大型多核 NUMA 系统上,cache-line 竞争效应可能是一点点可接受的开销,也可能是服务器性能问题的罪魁祸首。表 1 展示了用做测试的三台高端 HP x64-64 服务器3。所有这些机器采用一个常见的 NUMA 拓扑,即将处理器核与内存资源平均分布到各节点上。故没有杀马特式的 NUMA 使用场景9。每个插座,或者说节点,有 15 个核,内存也同样被均分。在一个大型的 NUMA 系统上,一个简单的自旋锁微测试就足够展示 cache-line 竞争效应。本例中,使用基于 Linux 3.0 的自旋锁实现,将一个只做获取和释放锁的密集循环跑上 100 万遍,就像 rcutorture 之类的压力测试程序所做的那样。
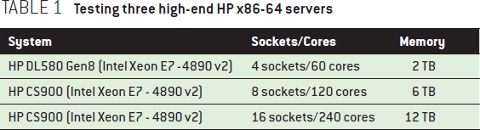
虽然现实中不会有那么变态的情形,但它很好展示了例如竞争锁等理论问题。另外,现实中也有类似行为的软件,故其竞争也是蛮激烈的。通过线程数和循环次数,能计算出 N 个 CPUs 竞争 cache-line 时,每个 CPU 每秒能进行的平均操作数。这个操作数,就作为本测试的吞吐量。
全面了解 cache-line 竞争效应必须包含单槽的情形,不然,无法从结果中排除 NUMA 相关因素和互联开销因素。这样做还能提供受影响最小的性能指标,便于对比有槽间通信的测试结果。图 1 展示了单个槽内,伴随核数的增加,吞吐量下降。
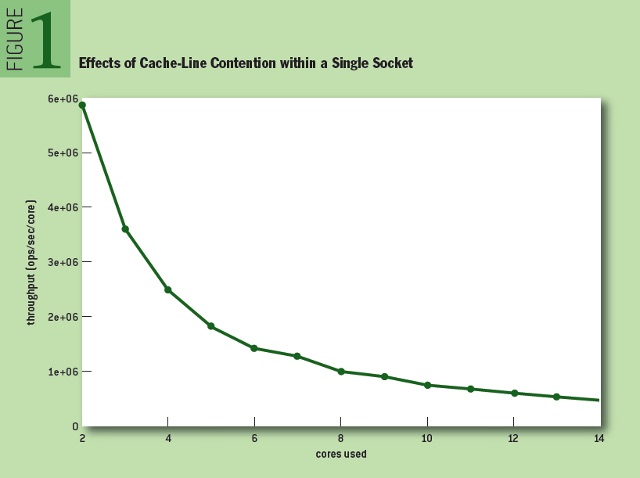
显而易见,伴随核数增加性能平滑下降。当使用单个槽中全部核时(即乘 7),相比双核情形性能下降 91.8%。这与程序员最初直觉 —— “任性地增加核数,多少能增加些性能吧”,刚好相反(译者:吐个槽,比平均的吞吐量能算数吗?有本事比总吞吐量,不过总吞吐量好像也比不上,可见确实下降很多)。再进一步说,在按照 NUMA 拓扑划分逻辑的软件架构下,这 91.8% 的衰减可视作最大性能损失。这种常见的构架,能避免访问远程内存带来高延时,尤其是在大型机器上。
当然,上述状况才不会变好呢,事实上会更糟。表 2 比较了单个槽 和 两个槽上 cache-line 竞争所产生影响。最显著的,莫过于 15 到 30 个核心时,吞吐量跌幅超过 80%。
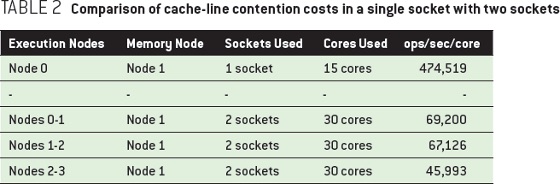
还有,使用两个槽时,访问位于远程内存中的锁,这很显然更糟,相比单槽跌幅会超过 90%。此时,测试的运行时间更让人揪心:完成百万次循环的时间从 2 秒 变成了 21 秒,后者访问的全是远程内存。
可见,评估竞争中,核的数目并不是唯一因素。如何分布也成了影响性能的关键因素,越少槽参与竞争 cache-line 性能越好3。随核数增加,FF(first fill)方法总是使用同个槽上的核,而 RR(round robin,循环)分布则会使用新槽上的核。
图 2 展示了“cache-line 之间” vs “cache-line 内部”的竞争概率,通过计算 100/槽数 来估算。在大型多槽系统上,随机挑选两核竞争同一 cache-line,槽越多,这两核同槽的几率就越低。
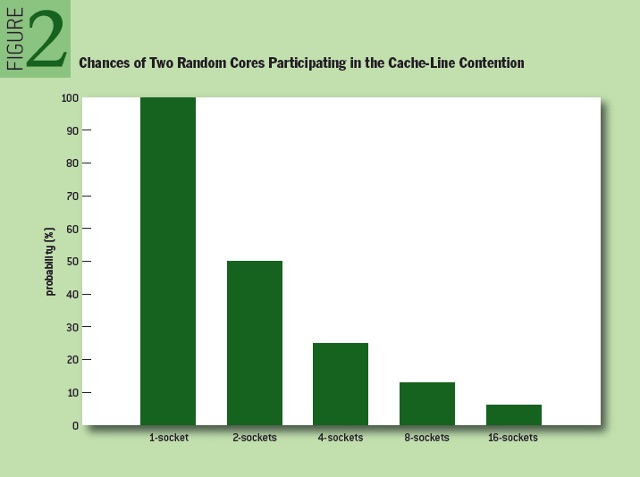
上图可见两槽和 16 槽的竞争情况完全不同,而两核不同槽对性能有毁灭性影响。这就是为啥较小系统上调优过的应用,不能直接放到扩充的硬件上 还期望性能“更好看”。如前述,增加 CPU 数,很可能带来 Linux 内部锁和 cache-line 的激烈竞争。
Queued/MSC:可伸缩的锁定
如前述,在大型硬件上,即便使用 CCAS 或 退避策略,忙等锁仍可能因 cache-line 激烈竞争而严重影响整体性能。在高度竞争时,其天生的非公平性带来了数量不定的 cache 未命中。而一个真正意义上的可伸缩锁,每每对其锁定,应有恒定数量的 cache 未命中 或 远程内存访问2,故不会有 不可伸缩锁上出现的、突然的性能暴跌。排队锁中,使线程旋等位于本地内存的锁,达到了真正的可伸缩性。此设计还保证了排队锁的公平:通常照 FIFO 顺序在排队等候的线程间传递锁的所有关系。排队锁的开销也很小,对于 n 线程 j 个锁,仅要求 O(n+j) 的空间占用15。作为对比,不可伸缩锁需要 O(nj)。绝大部分排队锁,例如有名的 MCS、K42 和 CLH,都维持着一个等候队列,每位旋等其在队列中的项。这些排队锁的区别在于如何维护队列,及必要的接口上的不同。
一个常见试验就是将普通的自旋锁(spinlock)替换为 MSC 锁2,3,在内核空间下(通常是 Linux 内核),总是产生很好的结果。图 3 展示了某个 MSC 实现原型的 AIM7 文件系统测试结果。该测试中,通过单个锁来串行化对各链表的并发操作。所有的 cache-line 竞争源自对这个全局锁的竞争。再引入未修改过的、 2.6 版本 Linux 中的自旋锁来对比看下。
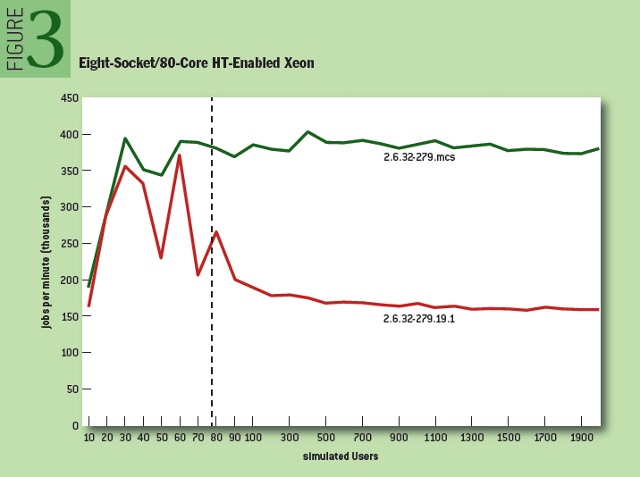
随着工作负载中,用户数越来越多,原生自旋锁这边,吞吐量(每分钟做完的活)很快往下走平,而 MSC 锁稳稳地领先大约 2.4 倍。资源管理器中,也能看到类似情况,54% 的系统时间(system time)降至仅仅 2% 。性能瓶颈就这样被彻底解决了。这里并没用其他优化工作 诸如细粒度化锁,故可肯定地说,单靠 MSC 锁,就取得了巨大性能增益。而 MSC 锁做的仅是最小化槽间 cache-line 数据通信。
最终,MSC 锁被 Linux 内核愉快收录2,特别用在了睡眠信号量的自旋逻辑中:在 mutexes 中的应用,使得某个流行的 Java 工作负载提升 248%,测试的系统为 16 槽, 240 核 HP Converged-System 900 并搭载 SAP HAHA 数据库。下述代码显示了 MSC 锁一些接口:
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked;
};
void mcs_spin_lock(struct mcs_spinlock **lock, struct mcs_spinlock *node);
void mcs_spin_unlock(struct mcs_spinlock **lock, struct mcs_spinlock *node);
大体看下:当某个线程需竞争锁时,以无等待方式加入到队列,加入时将本地节点作为参数,然后旋等自己的 cache line(即 node->locked ),直至轮到它来持锁。当前持锁的线程,释放时将锁传给链表中下一 CPU,从而造就了先来先得的公平性。该算法的有个缺点:任务加入队列的过程是将自己的本地节点的指针,写到上家的“->next 域”,这样上家释放锁时,可能有额外开销。
MSC 锁虽好,但也有忧桑,它用在普通的排队自旋锁(ticket spinlocks)中,会增大尺寸。而内核随处都用的自旋锁,不能超过 32位 字长。到头来,当前排队系统(ticketing system)用了其他有效的排队锁定方式17。
总结
心系性能来设计锁定原语,不仅是个广义上的好习惯,更能缓解将来的一些问题。本文内容源自大型化服务器上的经验及困扰 Linux 用户的现实问题。虽然 Donald E. Knuth 说过“不成熟的优化是万恶之源”,在锁定原语的实践中却得到了完全不同的说法。经验数据和实验告诉我们,误用锁 或是 无视锁的底层硬件行为 会付出沉重代价。另外,锁的用户和实现者,应特别关注锁是怎么用的,及锁的生命周期中,特别的设计会产生怎样的效果,例如不同程度的竞争。
在未来,随着计算机系统的演进,其处理能力的增加,锁定原语的理论和实践也要跟上,最终更好地利用硬件构架。即便现在,仍有非常专门的锁,例如 cohort 和 各种层次原语(hierarchical primitives),HCLH 正是后者的一种,在拥有基于队列的锁之优点同时,对内存局部性做优化,解决基于退避锁的公平性问题。
当然,改善锁定性能和伸缩性没有单一秘诀,还有更多与之相关的专题可供读者深入,例如无锁的数据结构,解决专有系统上的特殊限制 —— 例如优先级反转和实时环境的那些特点。类似的文章,应至少灌输一些意识,给那些挑灯夜战在大型系统上,苦逼面对伸缩问题的猿们。
致谢
Linux 内核中的伸缩方面的工作,是整个团队共同努力的成果,这中包括惠普(Hewlett-Packard)的 Linux 性能工作组,还有上游内核社区的宝贵意见和有趣讨论。特别感谢 Scott J. Norton,没有他的分析和实验数据,很难找出糟糕实现的原语之深刻内在。Paul E. Mckenney 的支持,还有 Samy Al Bahra 仔细审稿并给提建议,让本文更好了,我欠你们一杯。感谢 Jim Maurer 及 ACM Queue 小组其他人的支持和反馈。
法律声明
本文仅代表作者观点,未必是 SUSE LLC 官方观点。Linux 是 Linus Torvalds 注册的商标。其他公司,产品和服务的名称,可能也是他人的商标或服务商标。
参考
Al Bahra, S. 2013. Nonblocking algorithms and scalable multicore programming. ACM Queue 11(5).
Boyd-Wickizer, S. Kaashoek, F. M., Morris, R. Zeldovich, N. 2012. Non-scalable locks are dangerous. Proceedings of the Linux Symposium. Ottawa, Canada.
Bueso, D., Norton, S. J. 2014. An overview of kernel lock improvements. LinuxCon North America, Chicago, IL; http://events.linuxfoundation.org/sites/events/files/slides/linuxcon-2014-locking-final.pdf.
Corbet, J. 2013. Cramming more into struct page. LWN.net; http://lwn.net/Articles/565097/.
Corbet, J. 2013. Improving ticket spinlocks. LWN.net; http://lwn.net/Articles/531254/.
Crummey-Mellor, J. M., Scott, M. L. 1991. Algorithms for scalable synchronization on shared-memory multiprocessors. ACM Transactions of Computer Systems 9(1): 21-65.
Fuerst, S. 2014. Unfairness and locking. Lockless Inc.; http://locklessinc.com/articles/unfairness/.
Gray, J. N., Lorie, R. A., Putzolu, G. R., Traiger, I. L. 1975. Granularity of locks and degrees of consistency in a shared data base. San Jose, CA: IBM Research Laboratory.
Lameter, C. 2014. Normal and exotic use cases for NUMA features. Linux Foundation Collaboration Summit, Napa, CA.
McKenney, P. E. 2014. Is parallel programming hard, and, if so, what can you do about it?; https://www.kernel.org/pub/linux/kernel/people/paulmck/perfbook/perfbook.html.
McKenney, P. E., Boyd-Wickizer, S., Walpole, J. 2013. RCU usage in the Linux kernel: one decade later; http://www2.rdrop.com/users/paulmck/techreports/RCUUsage.2013.02.24a.pdf.
Molnar, I. Bueso, D. 2014. Design of the generic mutex subsystem. Linux kernel source code: documentation/mutex-design.txt.
van Riel, R., Bueso, D. 2013. ipc,sem: sysv semaphore scalability. LWN.net; http://lwn.net/Articles/543659/.
Rudolph, L., Segall, Z. 1984. Dynamic decentralized cache schemes for MIMD parallel processors. Proceedings of the 11th Annual International Symposium on Computer Architecture: 340-347.
Scott, M. L. 2013. Shared-memory synchronization. Synthesis Lectures on Computer Architecture. San Rafael, CA: Morgan & Claypool Publishers.
Unrau, R. C. Krieger, O. Gamsa, B., Stumm, M. 1994. Experiences with locking in a NUMA multiprocessor operating system kernel. Symposium on Operating Systems Design and Implementation; https://www.usenix.org/legacy/publications/library/proceedings/osdi/full_papers/unrau.a.
Zijlstra, P., Long, W. 2014. locking: qspinlock. LWN.net; http://lwn.net/Articles/590189/.
译者小絮
许多许多年以前,刚踏入开源教堂,那时还相信着 x11 窗口系统设计如何优雅,以至于用了几十年都不嫌旧。如今知道 x11 老矣,只是牵扯太复杂,重塑代价忒大。
最近也见新闻言Offset2lib攻击绕过64位Linux内核防护,似乎 Linux 内核到系统软件组合出来的安全机制脆脆的。
有人指出开发者社区的自大,像是历史上的天朝的感觉。只是有时如汉唐,令人拜服,正如本文所呈现那些精采;有时如晚清,令人叹讽。
没有什么是绝对完美的,甚至都算不上带着小瑕疵的完美。所以,开源不是信奉社区和项目,不是拜 Linux 教。开源应是置身于其中,带着独立思考,又在实际工作中或妥协或坚持,从而使世界更加美好了一些。
套用老罗去年的名言,“他们不是 Linux 的粉丝,他们是某种信念、某种价值观、某种理想、某种人生态度的粉丝,他们参与 Linux 社区,是因为能从中感受到这些东西”。
最后,再套用翻译中看到的一句话:本段仅代表本人观点,不代表泰晓官方。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
